






Destek Vektör Makineleri: Verilerin Derinliklerinde Keşfe Çıkmak
Veri dünyası, her geçen gün daha da derinleşiyor ve karmaşık hale geliyor. Bu karmaşık yapı içinde doğru bilgilere ulaşmak, bazen bir hazine avına dönüşebiliyor. İşte burada, Support Vector Machine yani SVM devreye giriyor. SVM, verileri analiz etmenin ve sınıflandırmanın etkili bir yolunu sunuyor. Bu blog yazısında, SVM algoritmasının nasıl çalıştığını, avantajlarını ve çeşitli uygulamalarını keşfedeceğiz. Çünkü verilerin derinliklerinde gerçek bilgiyi bulmak için doğru araçları kullanmak çok önemli. Hazırsanız, veri yolculuğuna çıkalım!
Ana Noktalar
- Support Vector Machine algoritması, verileri etkili bir şekilde sınıflandırır.
- SVM’nin çeşitli uygulama alanları bulunmaktadır.
- Model eğitimi süreci, SVM’nin başarısı için kritik öneme sahiptir.
Destek Vektör Makineleri Nedir? Temel Kavramlar
Hepimizin teknolojiyle iç içe yaşadığı bu günlerde, yapay zeka ile ilgili terimlerle sıkça karşılaşıyoruz. Bunlardan biri de Destek Vektör Makineleri, ya da kısaca SVM. Peki, bu kavram gerçekten nedir ve neden bu kadar popüler? Gelin, biraz derinlemesine inceleyelim.
Support Vector Machine Nedir?
Support Vector Machine, temel olarak bir makine öğrenme algoritmasıdır. Ama yalnızca basit bir algoritmadan fazlasıdır. Bu algoritma, verileri belirli sınıflara ayırmak için oldukça etkili bir yöntem sunar. Yani, elimizde bir veri kümesi varsa, bu veri kümesini ‘Kediler’ ve ‘Köpekler’ gibi sınıflara ayırmak için SVM kullanabiliriz. Ancak, bu algıyı tam anlamak için biraz daha açmakta fayda var.
SVM Algoritması Nasıl Çalışır?
SVM algoritması, temelde verileri en iyi şekilde ayıran bir hiperdüzlem bulmayı amaçlar. Düşünsenize, elimizde iki farklı veri grubu var. Bu grupları birbirinden ayırmak için bir çizgi çizeceğiz. Peki, bu çizgi nasıl en iyi şekilde yerleştirilir? İşte burada SVM devreye giriyor. Algoritma, en yakın verileri bulup, bu verilerle en geniş aralığı sağlayacak hiperdüzlemi oluşturmaya çalışır. Aklınızda karışıklık olabilir, bu yüzden şu aşamaları hatırlamak iyi olabilir:
- Veri Analizi: İlk olarak, veri setini inceleriz. Hangi özellikler var? Hangi sınıflara ayrılıyor?
- Hedef Belirleme: Hangi sınıfı tahmin etmek istiyoruz? Bunu netleştirmemiz gerekir.
- Model Eğitimi: Algoritmayı verilerle eğitiriz. Bu, modelin öğrenmesini sağlar.
- Model Testi: Eğitilen modeli yeni verilerle test ederiz. Bu sayede modelin başarısını ölçeriz.
Support Vector Machine Uygulamaları
Destek Vektör Makineleri, pek çok farklı alanda kullanılabilir. Ama gerçekten ne gibi uygulamalara sahip? İşte birkaç örnek:
- Metin Sınıflandırma: E-maillerin spam olup olmadığını belirlemek için kullanılabilir.
- Görüntü Tanıma: Yüz tanıma sistemlerinde oldukça etkilidir ve pratikte yaygın olarak kullanılıyor.
- Finansal Tahmin: Borsa verilerini analiz ederek gelecekteki trendleri tahmin etmeye yardımcı olabilir.
Özetle, Destek Vektör Makineleri, verileri anlamada ve sınıflandırmada oldukça güçlü bir araçtır. Ancak, kullanıcıların algoritmanın nasıl çalıştığını anlaması biraz zaman alabilir. Umarım bu yazı, SVM konusunda size yardımcı olur. Teknolojiyi anlamak için gösterdiğimiz çabalar her zaman karşılığını verir. Sonuçta, bu yalnızca bir algoritmanın ötesinde, verileri daha iyi analiz etmemizi sağlayan bir yöntemdir. Son olarak, aklınızda daha fazla soru varsa, lütfen çekinmeden yazın, birlikte tartışalım!
Destek Vektör Makinelerinin Tarihçesi ve Gelişimi
Destek Vektör Makineleri, ya da kısaca SVM, makine öğrenmesi dünyasında önemli bir yere sahiptir. İlk olarak 1992 yılında Vladimir Vapnik ve arkadaşı Alexey Chervonenkis tarafından geliştirildi. Başlangıçta, bu model, eğilimleri ve desenleri sınıflandırmak için ortaya çıktı. Ancak zamanla, birçok alanda etkili bir araç haline geldi. Peki, SVM’nin tarihçesine daha yakından bakalım.
İlk Gelişmeler ve Teorik Temeller
SVM’nin teorik temelleri 1960’lı yıllara kadar uzanıyor. O dönemde, en yakın komşu sınıflandırma algoritmaları popülerdi. Fakat Vapnik ve Chervonenkis, veriyi daha iyi ayırmanın yollarını aradı. Bu bağlamda, sınıflandırma için bir hiperdüzlem kullanarak sınıfları birbirinden ayırmayı önerdiler. İlk uygulamalarında, doğrusal ayırıcılar üzerinde yoğunlaştı. Ancak zamanla daha karmaşık yapılar da eklendi. Hatta, bu aşamada bazıları, “SVM sadece doğrusal veriler için mi geçerli?” sorusunu gündeme getirdi.
SVM’nin Yaygınlaşması
2000’li yılların başında SVM, özellikle veri madenciliği ve metin sınıflandırma gibi alanlarda geniş bir kullanıma ulaştı. O sıralar, bu metodun avantajları açıkça görülmeye başlandı. Özellikle, yüksek boyutlu verileri etkili bir şekilde ele alabilmesi ve genel kaçışın (overfitting) önüne geçebilmesi, onu birçok araştırmacının gözdesi haline getirdi. Ayrıca, diğer algoritmalara göre daha az veri gereksinimi, SVM’nin cazibesini artırdı.
Gelişen Yöntemler ve Uygulama Alanları
SVM’nin gelişimi durmadı. Yeni yöntemler ve algoritmalar geliştikçe, destek vektör makineleri de evrim geçirdi. Örneğin, çekirdek fonksiyonlarının kullanımı, verilerin daha esnek bir şekilde sınıflandırılmasını sağladı. Şu anda, SVM, sağlık, finans ve sosyal medya analitiği gibi birçok alanda kullanılıyor. Ancak, bazıları hala “SVM model eğitimi”nın karmaşıklığını sorguluyor. Oysa ki, eğitim süreci belli bir bilgiye sahip olduğunuzda oldukça sezgisel hale geliyor.
SVM’nin Avantajları ve Sınırları
SVM’nin en büyük avantajlarından biri, genel performansıdır. Yüksek doğruluk oranları sunması, onu birçok projede vazgeçilmez kılıyor. Ancak, her şey gibi, SVM’nin de limitleri var. Özellikle, büyük veri setlerinde eğitimin uzun sürmesi ve parametre ayarlamalarının zorluğu bazı kullanım durumlarını zorlaştırıyor. Yani, tüm bu etkenler, bazı durumlarda SVM’nin uygun bir seçenek olmaktan çıkmasına neden olabiliyor.
| Özellik | Avantajları | Dezavantajları |
|---|---|---|
| Doğruluk | Yüksek | Büyük veri setlerinde zorluk |
| Esneklik | Farklı çekirdek fonksiyonları kullanma imkanı | Parametre ayarlamalarının karmaşıklığı |
Sizce Destek Vektör Makineleri gelecekte hangi alanlarda daha fazla kullanılabilir? Ne dersiniz, SVM’yi daha da geliştirmek için hangi adımlar atılmalı? Belki de, her birimizin bu konuda bir katkısı vardır. Unutmayın, teknoloji her zaman gelişir, ama bunun arkasındaki fikirler ve motivasyonlar insana aittir.
SVM Algoritmasının Matematiksel Temelleri
Support Vector Machine (SVM) algoritması, makine öğreniminin en etkili araçlarından biri olarak karşımıza çıkıyor. Peki, SVM’i bu kadar özel kılan nedir? Temelinde, verileri en iyi şekilde ayırmayı hedefleyen bir yapı yatıyor. Bu ayrım, matematiksel bir temele dayanıyor. Bunu anlamak için birkaç temel kavramı gözden geçirelim.
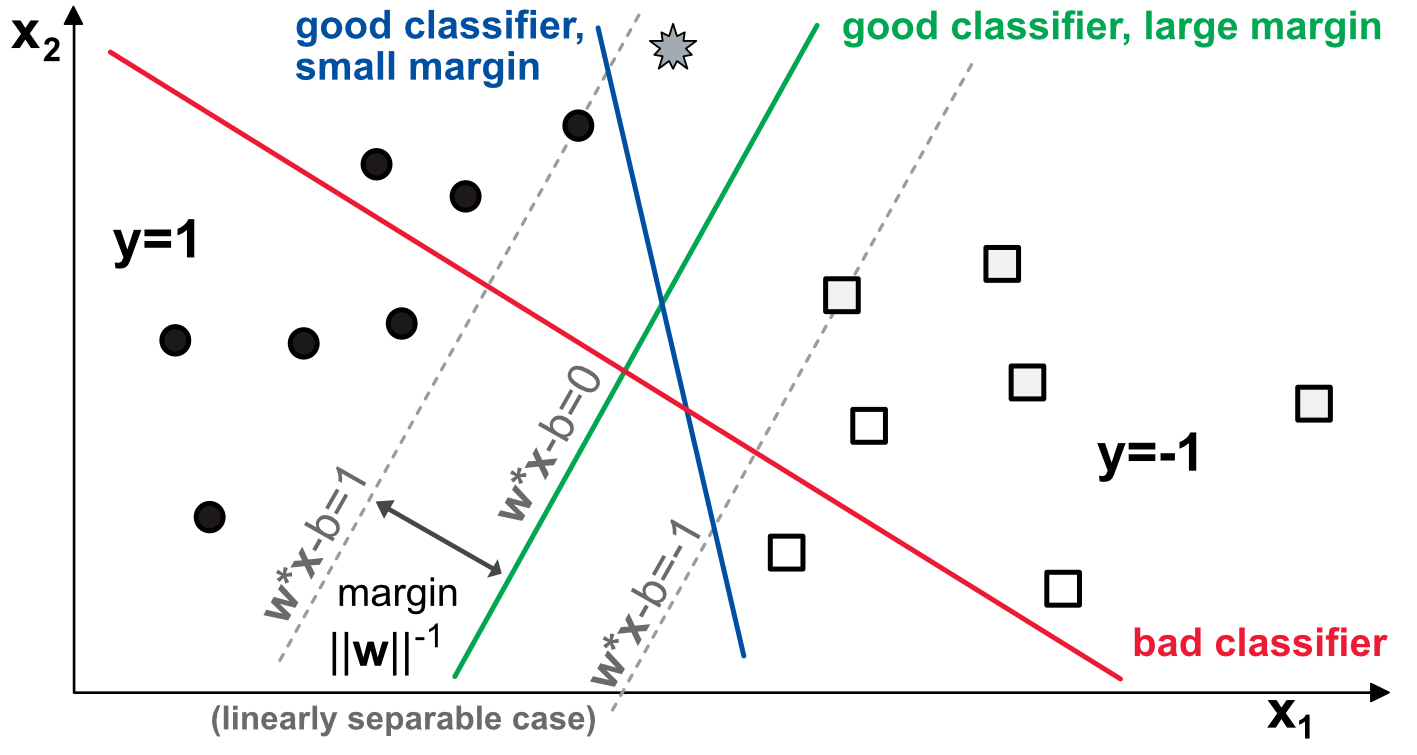
Hiper Düzlemlerin Önemi
SVM’in çalışma prensibi, iki veya daha fazla sınıfı ayırmak için bir hiper düzlem oluşturmak üstüne inşa edilmiştir. Bu düzlem, veriler arasındaki maksimum marjini sağlamak için seçilir. Yani, sınıfları ayırırken en uzak noktaları baz alır. Örneğin, verilerimiz iki farklı sınıfı temsil ediyorsa, SVM bu iki sınıf arasında bir düzlem oluşturur. Bununla birlikte, eğer veriler karmaşık bir yapıya sahipse, bu düzlemi daha yüksek boyutlara taşıyarak çözümler elde ederiz. Ne var ki, bu süreç her zaman göründüğü kadar basit değildir.
Destek Vektörleri Nedir?
Peki, burada “destek vektörleri” diye bir kavram duydunuz mu? İşte burası biraz kafa karıştırıcı olabilir, ama endişelenmeyin. Destek vektörleri, bu hiper düzlemin tam sınırında yer alan veri noktalarıdır. Yani, eğer bir veri noktası destek vektörüyse, bu o noktaların sınıfları arasında kritik bir rol oynadığını gösterir. Başka bir deyişle, SVM bu noktaları dikkate alarak karar verir. Bu gale, verilerinizi daha etkili bir şekilde sınıflandırmanıza yardımcı olur. Ancak her destek vektörü, her zaman en iyi sonucu vermez. Bazen, tüm verileri en iyi şekilde ayıracak bir düzlem bulmak, hayal ettiğiniz kadar kolay olmayabilir.
Matematiksel Formülasyon
Matematiksel açıdan bakıldığında, SVM’in formülasyonu, iki temel bileşenden oluşur: hedef fonksiyon ve sınırlayıcı koşullar. Hedef fonksiyon, destek vektörlerini kullanarak mümkün olan en büyük marjini bulmayı amaçlar. Bunun matematiksel göstergesi ise optimizasyon problemleriyle ifade edilir. Ama bu noktada, bazı matematiksel kavramlar ve terimler iç içe geçebilir, o yüzden dikkatli olmakta fayda var. Burada, ikili bir sıralama yapılır ve veriler arasındaki mesafe hesaplanır. Eğer üst üste binmeler varsa, bazı düzenlemelere gitmek gerekebilir. İşte bu düzenlemeler, SVM’in avantajlarını farklı kılar.
Sonuç olarak, SVM güçlü bir algoritma olmasına rağmen, matematiksel temelleri biraz karmaşık görünse de anlaşılması mümkündür. Özellikle, sınıflandırma ve regresyon gibi sorunları çözmede üstlendiği rol hayli belirgindir. Yine de, bu süreçte dikkatli olmak ve doğru verileri seçmek çok önemlidir. Çünkü doğru yapısal modelleme, SVM’in sonuçlarını doğrudan etkiler. Ve bu, verinizin doğasına bağlı olarak değişiklik gösterebilir. SVM algoritmasını daha derinlemesine kavrayabilmek için, bu matematiksel temeller üzerinde yoğunlaşmak kesinlikle faydalı olacaktır.
Veri Sınıflandırma ve Destek Vektör Makineleri
Merhaba sevgili okuyucular! Bugün çok heyecan verici bir konudan bahsedeceğiz: veri sınıflandırma ve bunun en popüler yöntemlerinden biri olan destek vektör makineleri. Günden güne artan veri miktarı, bu verileri anlamlı bilgilere dönüştürme ihtiyacını doğuruyor. Veri sınıflandırma, bu dönüşümde kilit bir rol oynuyor. Şimdi, bu konunun derinliklerine dalalım!
Veri Sınıflandırma Nedir?
Veri sınıflandırma, muhtemelen duyduğunuz bir kavram. Peki, tam olarak neyi ifade ediyor? Kısaca, verilerin belirli kategorilere ayrılması anlamına geliyor. Bu süreç, makine öğrenimi ve yapay zeka uygulamalarının temel taşlarından biri. Örneğin, e-postalarınızı spam ve spam olmayan olarak ayıran bir sistem düşünün. İşte tam burada veri sınıflandırma devreye giriyor.
Destek Vektör Makineleri (SVM) Nedir?
Şimdi başka bir terime geçelim: Destek Vektör Makineleri, ya da kısaca SVM. Bu yöntem, veri noktalarını ayrıştırmak için en iyi çizgiyi (veya düzlemi) bulmayı hedefler. Yani, elimizdeki verilerden en uygun ayırıcıyı bulmak için çalışır. Ancak, bu bazen karmaşık bir yapıya dönüşebilir. Çünkü, veri noktaları farklı boyutlarda ve formlarda olabilir. Ne kadar karmaşık gözükse de, SVM oldukça etkili bir yöntemdir.
SVM Nasıl Çalışır?
SVM, verileri en iyi şekilde ayırmak için birkaç adım izler. İşte bu adımlar:
- Veri noktalarını belirle: İlk adım, veri kümemizi tanımlamak.
- Ayrıştırıcı çizgiyi bul: İkinci adım, veri noktalarını en iyi biçimde ayıran çizgiyi veya düzlemi belirlemek.
- Hata oranını minimize et: Son olarak, elde edilen ayrıştırma ile hata oranını en aza indirmeye çalışmak.
Bu adımlar sonucunda, SVM belirlenen verileri oldukça başarılı bir şekilde sınıflandırabiliyor. Ancak, bazen verilerin karmaşıklığı ve boyutu sorun yaratabiliyor.
SVM’in Avantajları ve Dezavantajları
SVM kullanmanın bazı avantajları ve dezavantajları var. İşte bunlardan birkaçını inceleyelim:
| Avantajlar | Dezavantajlar |
|---|---|
| Yüksek doğru sınıflandırma oranı | Karmaşık ve büyük veri setlerinde yavaş kalabilir |
| Genel olarak iyi performans gösterir | Hiperparametre ayarları zor olabilir |
Görüyorsunuz ki, SVM’in bazı güçlü yönleri var, ama ayrıca dikkat edilmesi gereken noktalar da mevcut. Yani, her yöntemde olduğu gibi burada da bir denge sağlamak gerekiyor.
Sonuç
Kısacası, veri sınıflandırma ve destek vektör makineleri konusunda bilgi edinmek, teknolojinin ilerlemesi açısından çok önemli. Her geçen gün daha fazla veriyle karşılaşmak zorundayız ve bu verilerin bir düzen içine sokulması gerekiyor. SVM bu yolda etkili bir araç olarak karşımıza çıkıyor. Ancak, kullanırken avantajları ve dezavantajları göz önünde bulundurmakta fayda var.
Umarım bu makale hoşunuza gitmiştir. Veri sınıflandırma teknikleri ve SVM hakkında daha fazla bilgi almak isterseniz, bana ulaşabilirsiniz. Şimdilik hoşça kalın!
Çekirdek Fonksiyonları: SVM’de Gizli Güç
Destek Vektör Makineleri (SVM), makine öğrenmesi alanında sıkça kullanılan bir yöntemdir. Özellikle sınıflandırma ve regresyon problemlerinde oldukça etkili sonuçlar verir. Ancak, bunun en büyük nedeni, çekirdek fonksiyonlarıdır. Peki, bu çekirdek fonksiyonları nedir? Ne işe yararlar? Gelin, bu sorulara birlikte bakalım.
Çekirdek Fonksiyonlarının Rolü
Çekirdek fonksiyonları, veri noktalarını daha yüksek boyutlu uzaylara projekte ederek çalışır. Yani, verilerin aslında görünmeyen bir boyutta ilişki kurmalarını sağlar. Bu özellikleri sayesinde, doğrusal olarak ayrıştırılamayan verileri bile uygun bir şekilde sınıflandırabiliriz. Burada dikkat edilmesi gereken bir nokta var. Çekirdek fonksiyonunun nasıl seçildiğidir. Örneğin, bazen basit bir doğrusal çekirdek yeterli olurken, bazen daha karmaşık bir polinomsal çekirdek tercih etmek gerekebilir.
Farklı Çekirdek Türleri
Çekirdek fonksiyonları arasında en sık kullanılanlardan biri, gaussian çekirdektir. Bu çekirdek, verileri daha esnek bir şekilde ayırmamıza yardımcı olur. Özellikle çok sayıda veri noktası olduğunda, gaussian çekirdek oldukça iyi sonuçlar verebilir. Ancak, diğer taraftan, bazen veri setine uyum sağlamak için “overfitting” durumu yaşanabilir. Oysa, bir başka çekirdek türü olan polinomsal çekirdek, belirli bir derecede ayrım yapmaya olanak tanır. Bu da, verinin karmaşıklığına göre farklı seçimler yapmamıza imkan verir.
Çekirdek Seçiminin Zorluğu
Fakat şunu belirtmekte fayda var; çekirdek seçimi her zaman kolay değildir. Veriyi tanımadan doğru bir karar vermek zor olabilir. Bu noktada, deney ve yanılma yöntemine başvurmak genellikle kaçınılmazdır. Ancak, bu süreç, doğru çekirdeği bulmamız adına oldukça değerlidir. Sonuçta, doğru çekirdek fonksiyonu ile modelimizin başarısını artırabiliriz.
Sonuç olarak, destek vektör makinelerinde çekirdek fonksiyonları, gizli bir güç gibidir. Doğru seçim yapıldığında, büyük başarılar elde etmek mümkündür. Ancak, bu süreç biraz sabır ve deneyim gerektiriyor. Bu yüzden çalışmayı sürdürmek ve farklı çekirdeklerle denemeler yapmak çok önemlidir. Kim bilir, belki de aradığınız o gizli güç orada sizi bekliyordur!
SVM ve Diğer Makine Öğrenimi Yöntemleri: Karşılaştırmalı Analiz
Makine öğrenimi, günümüzde veri işlemeyi ve analiz etmeyi kolaylaştıran birçok yöntemi bünyesinde barındırıyor. Bu kapsamda, SVM (Support Vector Machine) yöntemi, kendine has avantajları ve dezavantajlarıyla dikkatleri üzerine çekiyor. Ancak, SVM’nin yanı sıra diğer makine öğrenimi yöntemleri de mevcut. Bu yazıda, SVM’yi, diğer popüler yöntemlerle karşılaştırarak daha net bir resim sunmaya çalışalım.
SVM Nedir ve Nasıl Çalışır?
SVM, sınıflandırma ve regresyon analizlerinde kullanılan bir yöntemdir. Veri kümesini mümkün olan en büyük boşlukla iki veya daha fazla sınıfa ayırmaya çalışır. Giriş verisi yüksek boyutlu bir uzayda temsil edildiğinden, SVM, verilerin en uygun ayrım hiper düzlemine yerleştirilmesine odaklanır. Ancak, bu durum bazen kafa karışıklığı yaratabilir. Çünkü veri boyutu arttıkça, hiper düzlemi bulmak zorlaşır ve bu da modelin performansını etkileyebilir.
“Ayrım hiper düzlemi, iki sınıf arasında en büyük mesafeyi sağlayan optimal bir ayırıcıdır.”
Diğer Yöntemlerle Karşılaştırma
SVM dışındaki makine öğrenimi yöntemleri de oldukça çeşitlidir. İşte SVM’nin en yaygın yöntemlerle karşılaştırıldığı bir tablo:
| Yöntem | Avantajları | Dezavantajları |
|---|---|---|
| SVM | Yüksek boyutlu verilerle iyi çalışır | Hesaplama açısından maliyetli olabilir |
| Karar Ağaçları | Kolay yorumlanabilir | Aşırı uyum riski vardır |
| Rastgele Orman | Yüksek doğruluk oranı sağlar | Model boyutu büyük olabilir |
Burada her bir yöntemin avantajları ve dezavantajları elbette farklı. Dolayısıyla, hangi yöntemi kullanmanız gerektiği, veri setinin özelliklerine bağlı olarak değişkenlik gösterebilir. Ayrıca, model seçiminde hedefinizin ne olduğu da önemli bir kriter. Bu nedenle, biraz deneme yanılma süreci de yaşamak gerekebilir. Ancak, unutmayalım ki hangi yöntemi seçerseniz seçin, sonuçlarınızı değerlendirirken dikkatli olmakta fayda var.
Kullanım Alanları
SVM, genellikle metin sınıflandırma, yüz tanıma ve genetik analiz gibi alanlarda kullanılır. Diğer yöntemler ise farklı alanlarda öne çıkmaktadır. Örneğin, karar ağaçları sağlık sektöründe teşhis koyma işleminde öne çıkarken, rastgele ormanlar finansal tahminlerde sıkça kullanılır. Bu noktada, her bir yöntemin güçlü ve zayıf yönlerini göz önünde bulundurmak gerekiyor.
Sonuç olarak, SVM ve diğer makine öğrenimi yöntemleri arasında kıyaslama yapmak, projenizin başarısı açısından kritik öneme sahiptir. En doğru seçimi yapmak için, veri setinizin yapısını iyi analiz etmeli ve her bir yöntemin potansiyelini dikkate almalısınız. Unutmayın, doğru yöntemle ilerlemek, veri biliminin bel kemiğini oluşturuyor!
Model Karmaşıklığı: Overfitting ve Underfitting Sorunları
Makine öğrenimi projelerimizde karşılaştığımız en temel sorunlardan biri model karmaşıklığıdır. Bu sorun, çoğu zaman overfitting ve underfitting durumlarıyla kendini gösterir. Bu yazıda bu kavramları detaylı bir şekilde ele alacağız ve ne anlama geldiklerini hep birlikte keşfedeceğiz. Şimdi gelin, bu konunun derinliklerine dalalım!
Overfitting Nedir?
Overfitting, bir modelin eğitim verisine fazla uyum sağlaması durumudur. Bu, modelin eğitim verisindeki gürültü ve istisnai durumları öğrenmesine yol açar. Sonuç olarak, model yeni veriler üzerinde tatmin edici bir performans gösteremez. Örneğin, bir modelin eğitim setindeki tüm örnekleri mükemmel şekilde öğrenmesi, fakat test setinde kötü performans sergilemesi durumunda overfitting olduğunu söyleyebiliriz. Peki, bu sorunu nasıl aşabiliriz? İşte birkaç öneri:
- Veri Augmentasyonu: Daha fazla veri oluşturarak modelin genelleme yeteneğini artırabiliriz.
- Regülerizasyon: Modelin karmaşıklığını azaltarak aşırı uyumu önleyebiliriz.
- Çapraz Doğrulama: Modeli farklı veri setleriyle test ederek gerçek performansını gözlemleyebiliriz.
Underfitting Nedir?
Diğer yandan, underfitting durumu, bir modelin eğitim verisindeki kalıpları yeterince öğrenememesi halidir. Kısacası, model veriyi basit bir şekilde yorumlayarak önemli bilgileri kaybeder. Bu durum genellikle basit bir model kullanıldığında veya yetersiz özellikler seçildiğinde ortaya çıkar. Underfitting ile başa çıkmak için aşağıdaki yöntemleri deneyebiliriz:
- Daha Karmaşık Modeller Kullanma: Modelin kapasitesini artırarak daha iyi öğrenmelerini sağlayabiliriz.
- Özellik Mühendisliği: Modelin başarılı olması için gerekli olan özellikleri belirleyip ekleyebiliriz.
- Veri Temizleme: Eğitim verilerinin kalitesini artırarak modelin daha iyi öğrenmesini sağlamak önemlidir.
Sonuç olarak, overfitting ve underfitting, model geliştirme sürecinde sıkça karşılaştığımız karmaşık durumlardır. Bu sorunlarla başa çıkmak için hem doğru teknikleri seçmeli hem de verimizi dikkatlice analiz etmeliyiz. Her iki durumu da göz önünde bulundurarak, doğru dengeyi bulmak başarının anahtarıdır. Unutmayalım ki, makine öğrenimi sadece veriyi öğrenmek değil, aynı zamanda bu veriyi en iyi şekilde yorumlamaktır.
Böylece, model karmaşıklığının tehlikeleri ve nasıl başa çıkabileceğimiz konusunu anlamış olduk. Umarım bu yazı, sizlere ilham verir ve projelerinizde yardımcı olur. Modelinizi dikkatlice tasarlayın; gürültüye kapılmamaya özen gösterin ve her zaman verilerinize güvenin. Başarılar!
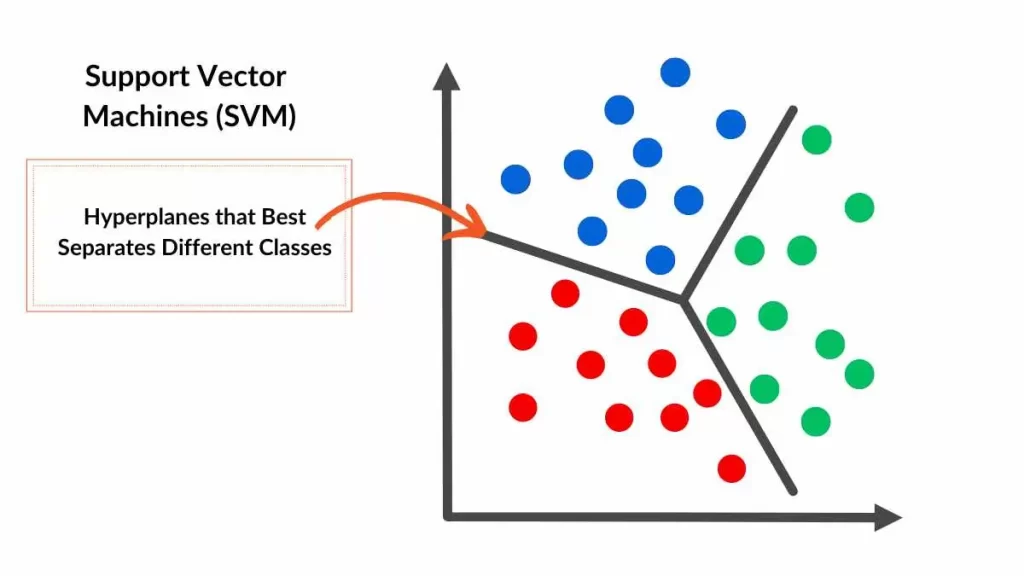
Destek Vektör Makineleri ile Çok Sınıflı Sınıflandırma
Merhaba! Bugün, destek vektör makineleri (SVM) ile çok sınıflı sınıflandırmanın büyülü dünyasına adım atacağız. SVM, birçok verimlilik ve doğrulukla sınıflandırma yapan bir yöntem olarak öne çıkıyor. Belki de bu konuyu ilk duyduğunuzda karmaşık gelebilir. Ancak, dilim döndüğünce bu teknikleri daha anlaşılır hale getirmeye çalışacağım.
SVM Nedir, Nasıl Çalışır?
Destek vektör makineleri, temel olarak verileri iki sınıfa ayırmayı hedefler. Ancak zamanla bu durum evrim geçirdi ve çok sınıflı sınıflandırma için de kullanılmaya başlandı. Yani, eğer elimizde birden fazla sınıf varsa, SVM bu sınıfları ayırt edebilir. Kullanım şeklinin basitliği ve etkili sonuçlar vermesi, onu popüler kılan nedenlerden sadece birkaçı.
Çok Sınıflı Sınıflandırmada Yöntemler
Peki, çok sınıflı bir sınıflandırma yaparken ne yapmalıyız? SVM, iki temel yöntemle çok sınıflı sınıflandırma gerçekleştirir:
| Yöntem | Açıklama |
|---|---|
| Bir-vs-Bir | Her iki sınıf için ayrı ayrı sınıflandırmalar oluşturur. Yani, her sınıf diğer sınıflarla karşılaştırılır. |
| Bir-vs-Hepsi | Her bir sınıf, diğer tüm sınıflara karşı ayrı bir model oluşturur. Sonuçta, her sınıf için en iyi tahmin yapılmaya çalışılır. |
Her iki yöntem de kendi içinde avantaj ve dezavantajlar barındırıyor. Örneğin, Bir-vs-Bir yöntemi çok sayıda sınıf olduğunda hesaplama açısından maliyetli olabilir. Ancak, daha doğruluk sunabilir. Bir-vs-Hepsi yöntemi ise daha az hesaplama gücü gerektirse de bazen yanılgıya neden olabilir.
Sonuç ve Öneriler
Destek vektör makineleri ile çok sınıflı sınıflandırma, veri analizi alanında güçlü bir araçtır. Ancak, elbette her şey gibi bu yönteminde artıları ve eksileri var. Eğer veriniz karmaşık ve çok katmanlıysa, SVM oldukça işinize yarayabilir. Benim önerim, uygulamalarınızı ve verilerinizi dikkatlice analiz etmektir. Ne de olsa, her veri seti kendine özgü bir yere sahiptir.
Unutmayın ki, SVM gibi yöntemlerin doğru kullanıldığında müthiş sonuçlar doğurduğunu görmek oldukça heyecan verici. Bu yazıda anladığımız temel prensiplerin yanı sıra, gerçek yaşamda bu tekniklerin nasıl uygulandığına dair daha fazla bilgi edinmek için deneyimler paylaşabilirsin. Sonuçta, bilgi paylaştıkça değerlenir. Belli ki bu yolculuk daha çok şey öğretecek!
Pratik Uygulamalar: Destek Vektör Makineleri Hangi Alanlarda Kullanılır?
Bugün biraz Destek Vektör Makineleri (SVM) dünyasına dalmak istiyorum. İlk olarak, bu tip bir makine öğrenimi algoritmasının ne kadar kapsamlı olduğunu anlamak önemlidir. SVM, sınıflandırma ve regresyon görevlerinde oldukça etkili bir yöntemdir. Ama yalnızca sınıflandırma ile sınırlı değil. Başka birçok alanda da adından söz ettiriyor.
Finans ve Ekonomi
Finans sektöründe sınıflandırma problemleri sıkça karşımıza çıkar. Örneğin, bir kredi başvurusunun onaylanıp onaylanmayacağına karar vermek için geçmiş verilere dayanarak bir model oluşturmak gerekiyor. Burada SVM, verileri analiz ederken hata payını en aza indirme amacı taşıyor. Bunun yanı sıra hisse senedi fiyat tahminlerinde de kullanılabiliyor. Ancak, bu durumu düşündüğümüzde, tahminlerin kesin olmadığını unutmamak gerekir. Ne de olsa finans dünyası her zaman tahmin edilemez bir yapıya sahip.
Sağlık Hizmetleri
Sağlık alanında ise SVM kullanımı, hastalık teşhisi gibi kritik görevlerde göz alıcı bir şekilde öne çıkıyor. Örneğin, kanser teşhisinde, tümörlerin özelliklerini sınıflandırmak amacıyla SVM uygulamaları kullanılıyor. Ancak burada dikkat edilmesi gereken bir nokta var. Yapay zeka ile karar vermek her zaman en doğru yaklaşım olmayabilir. Doktorların tecrübeleri, makinelerin analizleriyle harmanlandığında daha güvenilir sonuçlara ulaşılabiliyor. Bu nedenle insan faktörünü göz ardı etmemek gerekiyor.
Pazarlama ve Müşteri Analizi
Pazarlama alanında SVM, müşteri davranışlarını analiz etmek için sıklıkla tercih ediliyor. Müşterileri çeşitli kategorilere ayırarak hangi ürünlerin hangi gruplar için daha çekici olduğunu tespit etmek mümkün. Bu tür analizler, işletmelerin daha hedefli pazarlama stratejileri geliştirmelerine yardımcı oluyor. Ancak burada bir sorun var; bazen elde edilen veriler yanıltıcı olabilir. Yani, her analiz kesin sonuçlar vermeyebilir çünkü insanların davranışları düşündüğümüz kadar öngörülebilir olmayabilir. Bu durumda, veri analitiği ile birlikte insan zekasının kombinasyonu kritik bir rol oynar.
Görüntü Tanıma
SVM’nin bir diğer etkileyici kullanım alanı da görüntü tanıma sistemleridir. Fotoğraflardaki nesneleri tanımak ya da yüz tanımayı gerçekleştirmek konusunda oldukça etkili olduğunu biliyoruz. Ancak, bazen yüz algılama sistemleri, aynı görüntülerde benzer yüzleri ayırt etmekte zorlanabiliyor. Yani, ne kadar gelişmiş olursa olsun, teknoloji tamamen güvenilir değil. Bu yüzden, ek güvenlik önlemleri almak daima faydalı olabilir.
Sonuç olarak, Destek Vektör Makineleri, birçok alanda fark yaratan ve verimliliği artıran bir araçtır. Ancak, her teknolojide olduğu gibi burada da dikkatli olunmalı. Makineler, insan gibi düşünemez ve her zaman aynı sonuca ulaşmak için tasarlanmış değildir. Kısacası, bu uygulamalar açısından SVM, doğru bir şekilde kullanıldığında büyük fırsatlar sunabilir. Ancak bence, röportajlarda ve analizlerde bir insanın dokunuşu her zaman fark yaratır.
SVM Uygulamalarında Veri Ön İşleme Teknikleri
Merhaba sevgili okuyucular! Bugün, SVM yani Destek Vektör Makineleri uygulamalarında bir hayli önem taşıyan veri ön işleme tekniklerini birlikte keşfedeceğiz. Bu konunun üzerinde durmak, biraz kafa karıştırıcı olabilir ama bu yazıda netleştireceğiz! SVM, makine öğrenimi alanında sıkça kullanılan etkili bir yöntemdir. Ancak, verilerin düzgün bir şekilde işlenmesi, SVM’nin başarısını büyük ölçüde etkileyebilir. Hadi, birlikte bu tekniklerin neler olduğuna bakalım.
1. Veri Temizleme
Veri, bir hazine gibidir ama çoğu zaman işlenmeden önce içinde sorunlar barındırır. Yani, ilk adım veri temizliğidir. Peki, veri temizleme ne demektir? Aşağıdaki gibi bazı adımlar içerir:
- Eksik Veri Yönetimi: Verideki eksik değerlerin nasıl ele alınacağını belirlemek önemlidir. Bu değerler çıkarılabilir veya tahmin edilebilir.
- Aykırı Değerler: Verideki aşırı uç değerler, modelin performansını olumsuz etkileyebilir. Bu noktada, bu değerlerin nasıl ele alınacağına dair kararlara varılmalı.
2. Veri Dönüşümü
Veri temizlendikten sonra, verilerin uygun formatta olması gerekir. Burada veri dönüşümü süreci devreye girer. Bazı popüler veri dönüşüm yöntemleri şunlardır:
- Normalizasyon: Verilerin belirli bir aralığa (genellikle 0 ile 1) çekilmesidir. Böylece farklı ölçekteki veriler daha uyumlu hale gelir.
- Standardizasyon: Verilerin ortalaması 0 ve standart sapması 1 olacak şekilde düzenlenmesidir. Bu, bazı modellerin daha etkili çalışmasını sağlar.
3. Özellik Seçimi
Veri kümesindeki tüm özellikler her zaman gerekli değildir. Kimi zaman bazı özelliklerin gereksiz yere model karmaşıklığını artırdığı görülür. Bu noktada, özellik seçimi ile hangi özelliklerin kullanılacağını kesinleştirmek oldukça önemlidir. Bu süreç birkaç aşamadan oluşur:
- Filtre Yöntemleri: Bu yaklaşımda, özellikler istatistiksel yöntemlerle değerlendirilir ve en uygun olanlar belirlenir.
- Wrapper Yöntemleri: Bu yöntem, özelliklerin küçük gruplar halinde kullanılarak modelin başarısını ölçen bir yaklaşımdır.
4. Veri Augmentasyonu
Özellikle sınırlı veriye sahip olduğunuzda, veri augmentasyonu harika bir çözüm olabilir. Bu teknik, var olan verileri değiştirerek yeni veriler üretme sürecidir. Örneğin, görüntü verisinde döndürme, kaydırma veya renk değişiklikleri yaparak daha fazla veri elde edilebilir. Bu, modelin genel performansını artırır.
Sonuç olarak, SVM uygulamalarında bu veri ön işleme tekniklerini göz ardı etmemek oldukça önemlidir. Her bir adım, modelin başarısını doğrudan etkiler. Eğer bu teknikleri doğru bir şekilde uygularsanız, modelinizin performansı artar ve daha sağlıklı sonuçlar elde edersiniz. İşte böyle, arkadaşça bir dille paylaştığımız bu bilgiler umuyorum ki işinize yarar!
Hiperparametre Ayarlaması: Modelin Başarısını Artırmak
Hiperparametre ayarlaması, makine öğrenimi alanında oldukça önemli bir konu. Bir modelin performansını belirleyen birçok faktör var. Ancak bu faktörlerden biri de hiperparametreler. Onları doğru bir şekilde ayarlamak, modelimizin başarısını ciddi oranda artırabilir. Peki, bu hiperparametreler nedir ve neden bu kadar önemlidir?
Hiperparametre Nedir?
Önce bir çerçeve oluşturalım. Hiperparametreler, modelin öğrenim süreci boyunca değişmeyen, ancak öğrenim sürecini etkileyen parametrelerdir. Mesela, öğrenme oranı veya ağaç derinliği gibi. Bu parametreler, modelimizi belirli bir şekilde yönlendiriyor. Dolayısıyla, bu geleneksel ayarlama yöntemleri üzerinden çokça hareket edebiliriz. Ancak dikkatli olmak gerekiyor. Kötü ayarlanmış hiperparametreler işe yaramayan sonuçlara yol açabilir. Yani aslında, bir nevi bir denge kurmamız gerekiyor.
“Hiperparametreler, modelin ruhudur?”
Doğru Hiperparametre Ayarlaması Nasıl Yapılır?
Doğru hiperparametre ayarlaması yapmak, sadece tecrübe gerektirmiyor. Aynı zamanda, bir dizi yöntem uygulamak da önemli. İlk adımda, hiperparametre aralığını belirlemek gerekiyor. Bu aşamada dikkat edilmesi gereken şeyler var. Mesela, her hiperparametre için denememiz gereken birkaç farklı değer olmalı. Ancak bu işlem bazı durumlarda karmaşık olabilir. Böylece başımızı çok fazla ağrıtabilir. Ama sonuçta, bu çabaların da karşılığını alacağız.
Sonrasında, bu değerlerin kombinasyonlarını denememiz gerekebilir. Grid Search, Random Search gibi yöntemler kullanarak, modelin ne kadar iyi çalıştığını görebiliriz. Yalnız bu aşamada nokta atışı yapmak çok zordur. Çünkü bazen beklenmedik sonuçlarla karşılaşabiliriz. İşte bu yüzden, bazen yanlış stratejiler de izleyebiliriz. Ancak her yanlış deneme bize bir şeyler öğretir. Bu yüzden, sabırlı olmakta fayda var.
Sonuçlandırma: Neden Önemli?
Böyle bir süreçte bulunmak, sadece bir deneyim değil. Aynı zamanda, sürekli bir öğrenme yolculuğudur. Hiperparametre ayarlamasını gözardı edemeyiz, çünkü olmadığında modelimizin potansiyelini tam olarak kullanamıyoruz. Aynı zamanda, yanlış ayarlanan hiperparametreler, zaman kaybına yol açabilir.
Ne yazık ki, her şeyin mükemmel olması zor. Ancak pes etmeden yol almamız, yani denemelere açık olmamız gerekiyor. Gelişen teknolojilerle birlikte bu süreç daha da önem kazanacak. Kısacası, hiperparametre ayarlaması demek, modelin ruhunu yakından tanımak demektir.
SVM Performans Değerlendirme Yöntemleri
SVM (Destek Vektör Makineleri), makine öğrenmesinin popüler ve etkili bir yöntemidir. Ancak, bu güçlü aracın başarısını değerlendirmek için doğru performans ölçütlerini kullanmak oldukça önemlidir. Peki, SVM modeli nasıl değerlendirilir? Bu yazıda, SVM performans değerlendirme yöntemlerinin neler olduğunu daha yakından inceleyeceğiz.
Doğruluk (Accuracy)
Doğruluk, bir modelin ne kadar doğru tahmin yaptığını gösterir. Yani, doğru sınıflandırılan örneklerin toplam örneklere oranıdır. Ancak, bu sadece yüzeyde kalıyor gibi görünüyor. Çünkü bazı durumlarda, doğruluk yanıltıcı olabilir. Örneğin, dengesiz veri setlerine sahip olduğumuzda, model yüksek bir doğruluk değerine sahip olsa bile, pek de iç açıcı sonuçlar elde edemeyebiliriz.
Kesme Noktası (Threshold) Ayarlamaları
Bazen doğru tahminler yapmak için yalnızca doğruluğa güvenmek yeterli olmayabilir. Bu noktada, modelimizin kesme noktasını ayarlamamız gerekiyor. Kesme noktası, modelin pozitif veya negatif sınıfı nasıl belirleyeceğini gösterir. Yani, modelin tahmini yaparken hangi değerin “pozitif” olarak kabul edileceğine karar vermemizi sağlar. Bu ayarlamalar, modelin genel performansını artırabilir. Ancak, her zaman dikkatli olmakta fayda var!
F1 Skoru
F1 skoru, doğruluk ve hatırlama (recall) arasındaki dengeyi ölçer. Bu metrik, özellikle dengesiz veri setleri için oldukça yararlıdır. Yani, bir sınıfın diğerine göre çok daha fazla olduğu durumlarda, F1 skoru bize daha anlamlı bir performans göstergesi sunar. Ancak, bu hesaplamalar bazen kafa karıştırıcı olabilir. Çünkü yüksek F1 skoru, modelin her an her şeyi doğru bildiği anlamına gelmeyebilir!
Karmaşıklık Matrisi (Confusion Matrix)
Karmaşıklık matrisi, modelimizin tahminleri ile gerçek değerlerin karşılaştırılmasını sağlar. 2×2 boyutunda bir tablo şeklinde sunulan bu matris, doğru pozitif, yanlış pozitif, doğru negatif ve yanlış negatif sayısını gösterir. İlk başta biraz karmaşık görünebilir, ama aslında oldukça basit! Aşağıda karmaşıklık matrisinin genel bir yapısını görebilirsiniz:
| Gerçek Pozitif | Yanlış Pozitif |
|---|---|
| Doğru Pozitif | Doğru Negatif |
Kısacası, SVM performans değerlendirme yöntemleri, modelin ne kadar iyi çalıştığını anlamak için hayati öneme sahiptir. Doğruluk, F1 skoru, kesme noktası ayarlamaları ve karmaşıklık matrisi gibi araçlarla, modelimizin gerçek performansını daha net bir şekilde görebiliriz. Ancak, her yöntem kendi içinde belli başlı zorluklar barındırıyor. Bu yüzden, dikkatli ve bilinçli bir şekilde hareket etmekte fayda var. Unutmayın, makine öğrenmesi dünyası karmaşık ve sürekli evrilen bir alan!
Karmaşıklık ve Hesaplama Maliyeti: SVM’nin Sınırlamaları
Son zamanlarda makine öğrenimi alanında köklü değişiklikler yaşanıyor. Özellikle SVM (Destek Vektör Makineleri) gibi algoritmalar, birçok problemde etkili sonuçlar sağlamasıyla dikkat çekiyor. Ancak, bazen bu algoritmanın sınırlamaları göz ardı ediliyor. Peki, SVM’nin karmaşıklığı ve hesaplama maliyeti neden bu kadar önem kazandı? Gelin, birlikte derinlemesine inceleyelim.
Karmaşıklığın Derinlikleri
SVM’nin en belirgin özelliklerinden biri, yüksek boyutlu verilerle başa çıkma kapasitesidir. Ancak, bu durum aynı zamanda karmaşıklığı da beraberinde getirir. Yüksek boyutlu bir uzayda, verilerin ayrıştırılması için gereken parametre sayısı artar. Bu durumda, gerek modelin eğitimi gerekse tahmin süreci oldukça zorlaşır. Peki, bu karmaşıklık hangi sorunları gündeme getirir?
- Overfitting Riski: Çok karmaşık modeller, eğitim verisine fazla uyum sağlayarak genel performansı düşürebilir.
- Yüksek Hesaplama Maliyeti: Sadece eğitim sürecinde değil, gerçek zamanlı tahminlerde de yüksek hesaplama gücü gerektirir.
- Model Seçimi Zorluğu: Uygun hiperparametrelerin seçilmesi, deneyim ve zaman gerektirir, bu da süreçleri karmaşık hale getirir.
Hesaplama Maliyeti ve Zaman Yönetimi
Bazı durumlarda, SVM’yi kullanmak demek, ölçüsüz bir hesaplama maliyetine katlanmak anlamına gelebilir. Özellikle büyük veri setleri ile çalışırken, bu maliyetin büyüklüğü göz korkutucu olabilir. Tam anlamıyla algoritmanın etkinliğinden faydalanabilmek için yapılan hesaplamalar, çok uzun fakir süreler alabiliyor. Bunun yanı sıra, şu noktaları da göz önünde bulundurmakta fayda var:
- Veri Ön İşleme Gereksinimi: SVM’nin etkili çalışabilmesi için verilerin mutlaka ön işleme tabi tutulması gerekir.
- Uyum Süreci: Modelin iyi bir performans sergileyebilmesi için uygun kernel fonksiyonunun seçilmesi şarttır.
- İşlemci Kaynakları: Yalnızca eğitim süreci değil, aynı zamanda tahmin aşamasında da ciddi kaynak tüketimi söz konusudur.
Görüldüğü üzere, SVM yüksek etkili sonuçlar sağlasa da karmaşıklık ve hesaplama maliyeti açısından kendine has zorlukları birlikte getiriyor. Sadece güçlü bir model geliştirmek yeterli değil; modelin sürdürülebilir ve verimli olabilmesi için hesaplama maliyetlerini iyi yönetmek gerekiyor. Ne var ki, bu durum bazen bilgi yoğunluğu oluşturuyor. Ancak, SVM gibi teknikleri dikkatlice kullanmak, gerçek anlamda fayda sağlamanın anahtarıdır.
Sonuç olarak, SVM hayal edebileceğinizden çok daha karmaşık bir yapı sunuyor. Bu karmaşıklığı anlamak ve yönetmek ise, makine öğrenimi serüveninizdeki önemli adımlardan biri olacaktır. Unutmayın ki, bir algoritmanın ne kadar etkili olduğuna karar verirken, onun sınırlamalarını da göz önünde bulundurmakta fayda var.
Gelecekte Destek Vektör Makineleri: Araştırma ve Yenilikler
Destek Vektör Makineleri (SVM), yapay zeka dünyasında uzun bir yol kat etti. Geçmişten günümüze bu algoritmanın nasıl geliştiğini gözlemlemek oldukça ilginç. Ancak gelecekte neler olabileceği üzerinde düşünmek, belki de daha da heyecan verici. SVM’nin geleceği, yalnızca algoritmanın kendisiyle sınırlı değil; aynı zamanda uygulama alanları ve elde edilen sonuçlarla dolu bir evren sunuyor. O zaman gelin, bu ilginç yolculuğa birlikte çıkalım.
SVM’nin Mevcut Durumu
Bugün, SVM genellikle sınıflandırma ve regresyon görevlerinde kullanılıyor. Örneğin, tıbbi görüntüleme, finansal tahminler veya metin sınıflandırma gibi birçok alanda etkili bir biçimde yer buluyor. Fakat bence, burada dikkat edilmesi gereken bazı önemli noktalar var. Bu noktalar, SVM’nin sağladığı avantajlar ve dezavantajların bütünlüğünü oluşturuyor.
| Avantajlar | Dezavantajlar |
|---|---|
| Yüksek doğruluk oranı | Yüksek hesaplama maliyeti |
| Çeşkilli veri setlerinde etkinliği | Büyük verilerle çalışmakta zorlanma |
Sonuç olarak, SVM hala oldukça güçlü ve faydalı bir metodoloji. Ancak, bu durumun zamanla değişebileceğini unutmamak gerekiyor. Peki, gelecekte bu teknoloji nereye gidecek? İşte burası oldukça kafa karıştırıcı.
Gelecekteki Yenilikler ve Olasılıklar
Gelecekte, SVM’nin yeni algoritmalarla entegre olması durumu söz konusu. Mesela, derin öğrenmenin etkileri SVM üzerinde kendini gösterebilir. Böylece, daha akıllı ve adaptif sistemler ortaya çıkabilir. Yine de bu sinerji, bazı zorluklar da getirebilir. Özellikle, bu tür üretken entegrasyonların hesaplama gücü gereksinimlerini nasıl yöneteceğimiz konusunda kafa karışıklığı yaratması muhtemel.
Ek olarak, veri gizliliği ve etik konuların daha ön planda olacağını öngörüyorum. Örneğin, kişisel verilerin güvenliği açısından SVM uygulamaları nasıl yönetilecek? Bu tür sorular, teknoloji geliştiricilerini ve araştırmacıları düşündürüyor.
Son Çizgi
Kısacası, Destek Vektör Makineleri’nin geleceği oldukça parlak görünüyor. Ancak bunun yanı sıra, yeni zorlukların ve soruların da kapısını aralıyor. Geliştiriciler ve araştırmacılar, bu sürecin neresinde yer alacak? Bunu zaman gösterecek. Hâlâ SVM’yi daha iyi hale getirmek için yapılacak çok şey var ve belki de en önemlisi, bu yolculukta birlikte ilerlemek.
Umarım bu yazı, SVM’nin geleceğine dair düşüncelerimizi geliştirmeye yardımcı olmuştur. Unutmayın, önemli olan yalnızca teknik bilgi değil, ayrıca bu bilgiyi nasıl uygulayacağımızdır. Gelecek için merakla beklediğiniz her türlü soru veya düşünceyi paylaşabilirsiniz!
Başarılı SVM Projeleri: Örnek Vaka Çalışmaları
Günümüzde makine öğrenmesi alanında birçok farklı teknik bulunmaktadır. Ancak, SVM (Destek Vektör Makineleri) gibi güçlü yöntemler hâlâ popülerliğini koruyor. Özellikle sınıflandırma ve regresyon problemlerinde birçok projede başarı yakalamış bir teknik olarak öne çıkıyor. Şimdi, bu teknikle gerçekleştirilmiş bazı ilham verici projelere göz atalım.
1. Sağlık Sektöründe Hastalık Teşhisi
Sağlık alanında, yapay zeka kullanarak hastalıkların daha hızlı ve doğru bir şekilde teşhis edilmesi büyük bir ayrıcalık. Bir grup araştırmacı, SVM yöntemini kullanarak kanser teşhis sistemleri geliştirdi. Bu sistem, hastaların tıbbi verilerini analiz ederek hangi hastalık olasılıklarının daha yüksek olduğunu belirliyor. Ne var ki, bazı hastalarda yanlış pozitif sonuç verme ihtimali olduğu için ek veri setleriyle çalışmak zorunda kaldılar. Yine de, elde ettikleri başarı %90’ın üzerinde bir doğruluk oranıydı!
2. Müşteri Segmentasyonu: İş Dünyasında Yenilikçilik
İş dünyasında müşteri segmentasyonu yapmak, pazarlama stratejilerinin belirlenmesinde hayati öneme sahiptir. Bir online perakendeci, SVM kullanarak müşteri verilerini analiz etti ve farklı segmentlerdeki müşterilerin alışveriş alışkanlıklarını belirledi. Bununla birlikte, bazı verilerin eksik olması işleri karmaşıklaştırdı. Ama sonuçta, bu projeyle beraber pazarlama kampanyaları daha hedefli hale getirildi. Sonuçta, satışlar ciddi şekilde arttı!
3. Görüntü Tanıma Uygulamaları
SVM, görüntü tanıma sistemlerinde de sıkça tercih edilen bir yöntem. Bir grup mühendis, yüz tanıma uygulamaları geliştirmek için SVM’yi kullandı. Proje sırasında, farklı açılardan ve ışık koşullarından gelen görsellerle çalışmak durumunda kaldılar. Bu, bazı kafa karışıklıklarına neden oldu. Ancak, teknik ilerlemeleri sayesinde sistem, %95 oranında doğru yüz tanıma sonuçları elde etti. Bu uygulama, güvenlik sistemlerinden sosyal medya platformlarına kadar geniş bir yelpazede kullanıma sunuldu.
Sonuç olarak, bu projeler SVM yönteminin gücünü ortaya koyuyor. İster sağlık, ister iş dünyası, ister görüntü tanıma olsun, SVM’nin sunduğu olanaklar gerçekten etkileyici. Belki siz de kendi projenizde bu bilgileri kullanabilirsiniz, kim bilir? Sonuçta, başarılı projelerin ardında doğru teknikler ve yenilikçi düşünceler yatıyor!
Bunları da İnceleyebilirsiniz:
Nedir Bu Destek Vektör Makineleri? (Makine Öğrenmesi Serisi-2)
Sonuç
Sonuç olarak, Destek Vektör Makineleri (SVM), karmaşık verilerle başa çıkma konusunda sahip olduğu güçlü yetenekleri ile dikkat çekiyor. Gerçek dünya verileri, bazen kaotik ve öngörülemez olabiliyor. Ancak SVM, bu verilerin derinliklerindeki desenleri keşfederken bize büyük bir yardımcı oluyor. Bu yöntem, sınıflandırma ve regresyon problemlerinde sağladığı başarı ile araştırmacılardan endüstri profesyonellerine kadar birçok kişi tarafından tercih ediliyor. Özellikle yüksek boyutlu verilerle çalışırken, SVM’nin sunduğu doğruluk ve etkilik oldukça faydalı. Gelecekte bu teknolojinin daha da gelişeceğini ve yaşamımızın birçok alanında kendine yer bulacağına inanıyorum. Fakat her teknoloji gibi, SVM’nin de sınırlamaları olduğunu unutmamak gerek. Bu nedenle, onu en etkili şekilde kullanmak için sürekli öğrenmek ve denemek şart. Verilerin derinliklerine doğru yapacağımız keşiflerde, SVM bize yeni kapılar açmaya devam edecek.
Sıkça Sorulan Sorular
Destek Vektör Makineleri (SVM) nedir?
Destek Vektör Makineleri, sınıflandırma ve regresyon analizinde kullanılan bir denetimli öğrenme algoritmasıdır. Verileri yüksek boyutlu bir uzaya dönüştürerek en iyi ayrım çizgisini bulmayı hedefler.
SVM nasıl çalışır?
SVM, verileri iki sınıfa ayıran en iyi hiper düzlemi (ayrım çizgisi) bulmaya çalışır. Bu, her iki sınıfa en uzak noktaların (destek vektörleri) kullanılmasıyla gerçekleştirilir.
SVM hangi durumlarda kullanılır?
SVM, ikili sınıflandırma problemleri için yaygın olarak kullanılır. Ayrıca birden çok sınıf içeren problemler için de uzantıları mevcuttur.
SVM’nin avantajları nelerdir?
SVM, yüksek boyutlu uzaylarda etkili sonuçlar verir, genelleme yeteneği yüksektir ve karmaşık ayırma sınırlarını öğrenebilir.
SVM’nin dezavantajları nelerdir?
SVM, büyük veri setleri ile çalışırken yavaşlayabilir ve parametre ayarlamaları zorlayıcı olabilir. Ayrıca, gürültülü verilerle başa çıkması zor olabilir.
Kernels nedir ve SVM’de nasıl kullanılır?
Kernels, verilerin daha yüksek boyutlu bir uzaya dönüştürülmesini sağlayan matematiksel fonksiyonlardır. SVM’de, lineer olmayan ayrım çizgileri bulmak için farklı kernel’ler kullanılabilir.
SVM ve Naive Bayes arasındaki fark nedir?
SVM, verileri ayırmak için maksimum marjı ararken, Naive Bayes, olasılık tabanlı bir yaklaşımla çalışır. Bu nedenle, SVM genellikle daha karmaşık ve doğrusal olmayan problemlerde önceki bir model olarak daha iyi performans gösterebilir.
SVM ile büyük veri kümesi ile nasıl başa çıkılır?
Büyük veri kümesi kullanıldığında, SVM’nin performansını artırmak için örnekleme, boyut indirgeme ve paralel hesaplama yöntemleri kullanılabilir.
SVM sonucu yorumlarken neler dikkate alınmalıdır?
SVM modeli sonuçlarını yorumlarken, doğruluk, hatalı sınıflandırma oranı ve destek vektörlerinin sayısı gibi metrikler dikkate alınmalıdır.
SVM’nin uygulama alanları nelerdir?
SVM, yüz tanıma, metin sınıflandırma, el yazısı tanıma, biyolojik bilgi analizleri ve daha birçok alanda yaygın olarak kullanılmaktadır.
















Siz ne düşünüyorsunuz?
Düşüncelerinizin farkına varmak güzel. Bir yorum bırakın.